Machine learning underpins a lot of the efficiency of the internet — if it weren’t for computers making decisions, your inbox would be overrun with spam mail, the ads you see would all be low quality, and the search results you get would be largely irrelevant. Many of the algorithms that get the most use are classifiers, that is algorithms that analyze an input and decide whether to apply a label. In the case of spam, the label that a spam classifier applies to an email is one of two: spam or not spam.
To learn more about how the performance of classifiers can be evaluated, imagine the following 20 emails, 15 of which are not spam, and 5 of which are spammy:
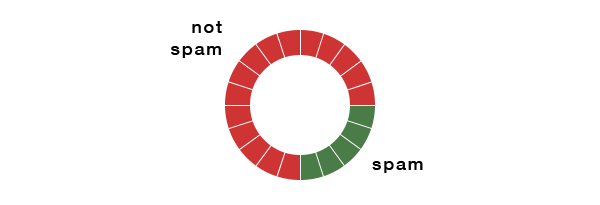
When we run a classifier algorithm, it will create verdicts about each piece of content by applying a label:
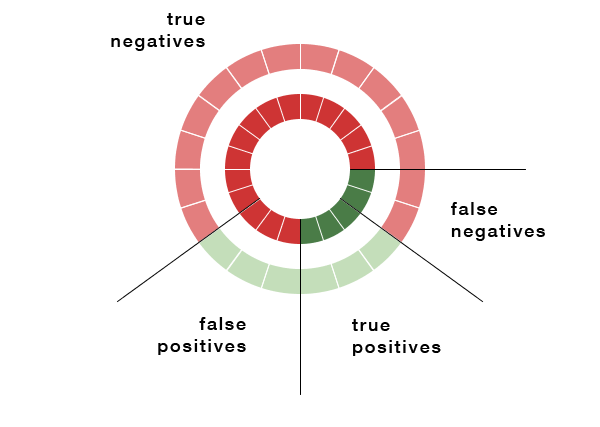
Obviously, since some of the messages haven’t been encountered before, and others might be difficult to classify because of conflicting signals, some of the emails will be misclassified. The emails that are actually spam but were marked clean consitute the false negatives , while the pieces of content that aren’t spam but were labeled as such are the false positives .
Obviously, we would like the false positive rate and the false negative rate to be as low as possible, because that would mean we are classifying accurately. There are two metrics, precision and recall , that can help us further understand the performance of the classifier.
Precision
Precision is defined by (#TruePositives) / (#True Positives + #False Positives) . The question that this metric answers is:
“of all things that were labeled as spam, how many were actually spam?”
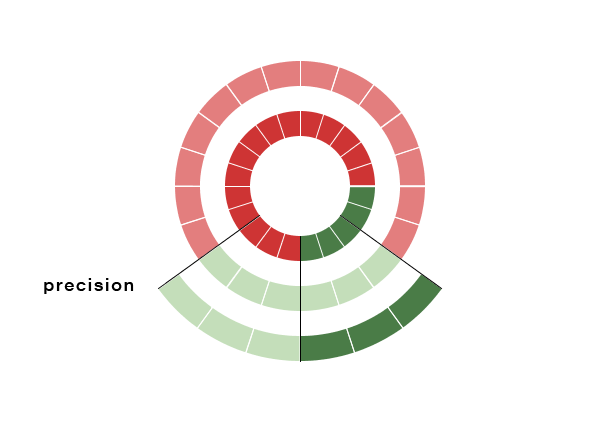
This toy example has 50% precision, meaning that only half of the emails that we labeled as spam were indeed spammy.
Recall
A related metric is recall, which is defined as (#TruePositives) / (#True Positives + #False Negatives) . What recall measures is:
“of all the things that are truly spam, how many did we label?”
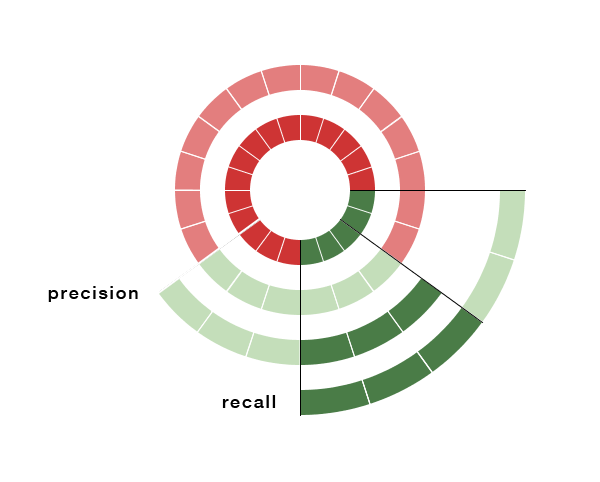
As you can see from the example, our algorithm has 60% recall. Only two of the truly spammy emails were not caught by the algorithm.
To understand the differences between these metrics better, it’s illustrative to look at some extreme cases.
High precision, low recall
If we have an algorithm with high precision, we can trust the classification judgements made by it. In this example, the algorithm ran has 100% precision, since the one piece of content that it did label was in fact spammy.
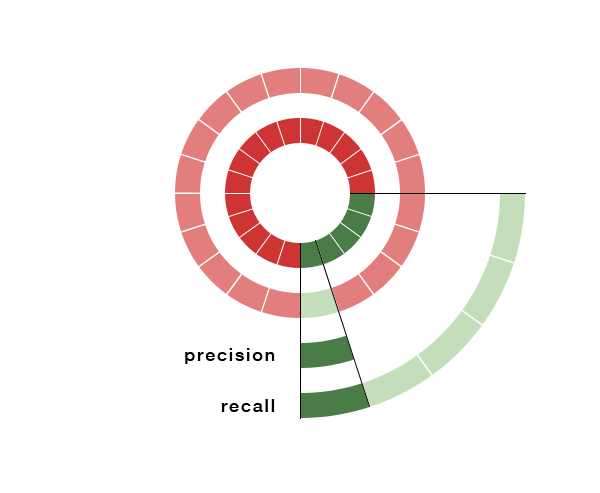
However, this particular algorithm is very conservative, and has a very low rate of recall (20%), meaning that much of the spammy content in the original corpus remained unidentified. This might be good if you are worried about incorrectly classifying good user’s content as bad, but is ineffective in actually stopping bad content.
Low precision, high recall
The other extreme would be an algorithm that labels each of the truly spammy cases correctly, but also labels a whole bunch of innocuous emails as spam:
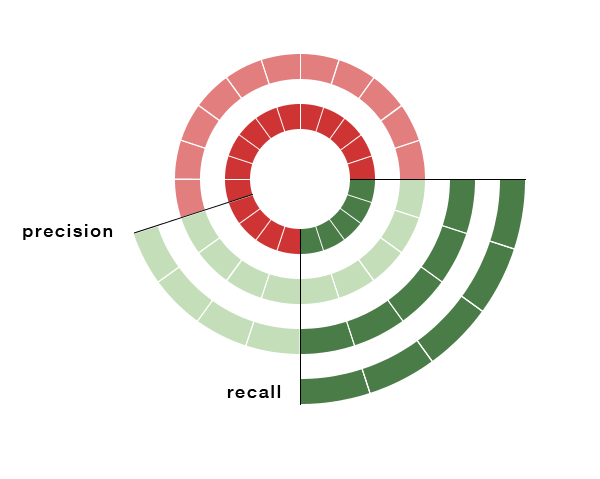
Algorithms that are too liberal in making classifications lead to this result, in this case, with only 55% precision.
Normally, there is a tradeoff between precision and recall, as an algorithm is tuned between the extremes of conservatism and liberalism with the application of labels. This intricate balance is what makes working with classifiers both so challenging and rewarding.